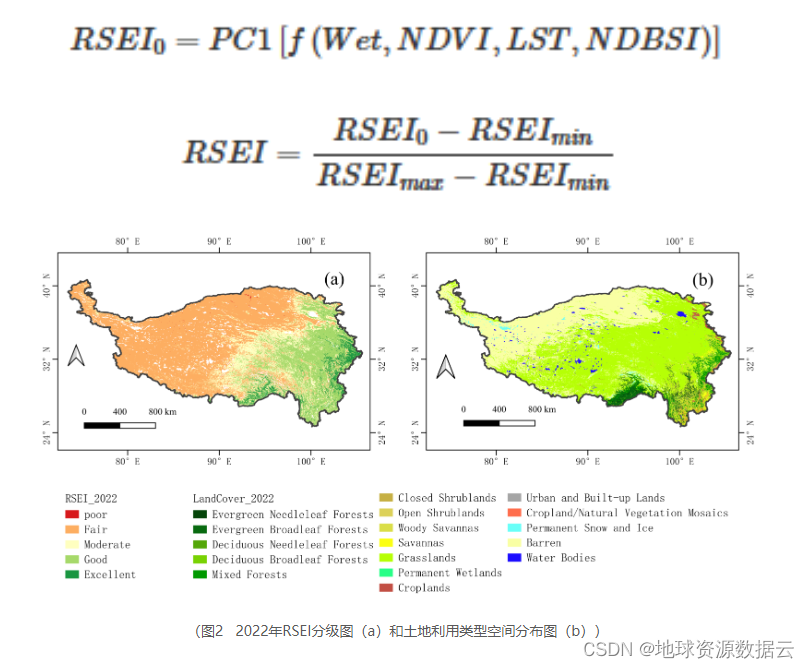
前言
_
万字教程!奶奶看了都会的 ComfyUI 入门教程
推荐阅读 一、川言川语 大家好,我是言川。
阅读文章 >
](https://www.uisdc.com/comfyui-3)
目前使用 Stable Diffusion 进行创作的工具主要有两个:WebUI 和 ComfyUI。而更晚出现的 ComfyUI 凭借超高的可定制性和复现性迅速火遍全球。有设计师表示 SD 发布了 XL1.0 后,ComfyUI 用它优秀的底层逻辑率先打击了臃肿不稳定的 WebUI1.6,成为更适合“体验”XL 的 SD 生图工具。
本文就来具体介绍一下 ComfyUI 是什么?为什么好?怎么用?
一、ComfyUI 简介
ComfyUI 是一个专为 Stable Diffusion 设计的基于节点的图形用户界面(GUI),简单来说就是将整个图像生成过程分解为多个独立的节点,每个节点都有自己独立的功能,例如加载模型,文本提示,生成图片等等。每个模块通过输入和输出的线连在一起变成一个完整的工作流。
整个过程用户可以灵活的调整和配置不同的功能节点,这就代表整个模型更加自由,控制更加精准。
二、LDM 底层逻辑
相比于 WebUI,ComfyUI 的工作流模式更加贴近 Stable Diffusion 的底层运行逻辑,这对于新手来说有一定的学习门槛,但是在完全掌握以后使用 ComfyUI 将会变得非常轻松,同时在 AI 盛行的时代,懂得一些底层逻辑也有助于设计师后续的发展。所以本文将结合 SD 的底层逻辑和大家简单解释 ComfyUI 的基础节点。
Stable Diffusion 之所以叫 Stable,是因为公司叫 StabilityAI。其基础模型是 Latent Diffusion Model(LDM),翻译为潜在扩散模型,可以理解为主要的图片生成流程都在一个叫「latent space(潜在空间)」的魔法盒子里进行。
图片在这个空间存在的方式是我们无法识别的向量,我们只需要知道这些我们无法识别的东西所表示的信息和图片相差无几,但是数据尺寸却变得非常小就行,这是一个类似于压缩的过程,所以在这个空间中进行运行可以大大缩小运行内存。
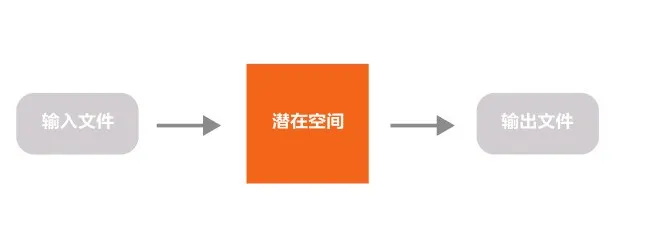
这个过程可以简单理解为,向潜在空间输入文件,数据经过处理生成图片并输出。
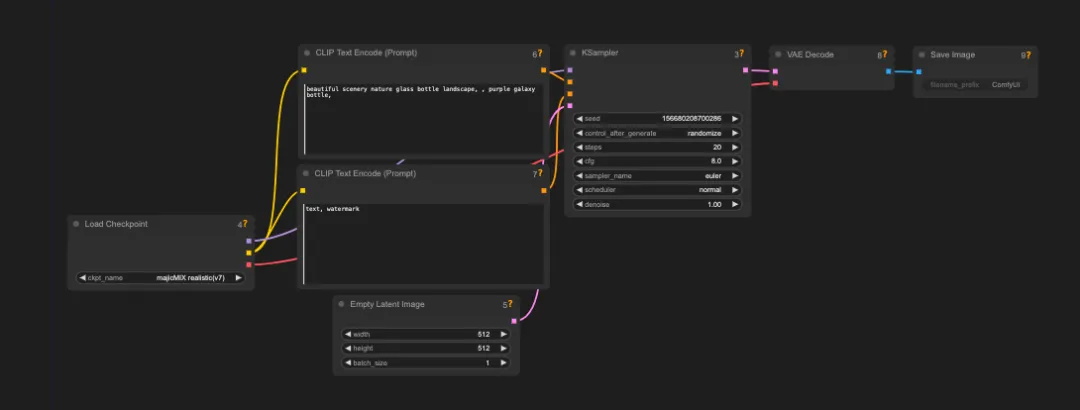
以文本生图为例,我们现在来解释整个流程中包含的节点及作用。
输入文件包含了我们熟知的常规内容:文本和图片,也就对应着 Text2Image 和 Image2Image。但是文本内容计算机是无法理解的,所以我们需要将文本转换为计算机能够理解的信息,这个过程使用了 Clip 模型。(图片的转换是使用了 VAE 模型)
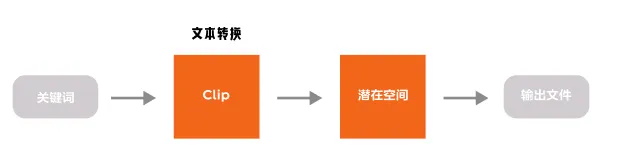
熟悉 WebUI 的朋友可以知道,控制模型实际生成部分的模型是 KSampler(采样器),在这其中我们可以控制迭代次数,种子数等等。而这个步骤就发生在潜在空间中。
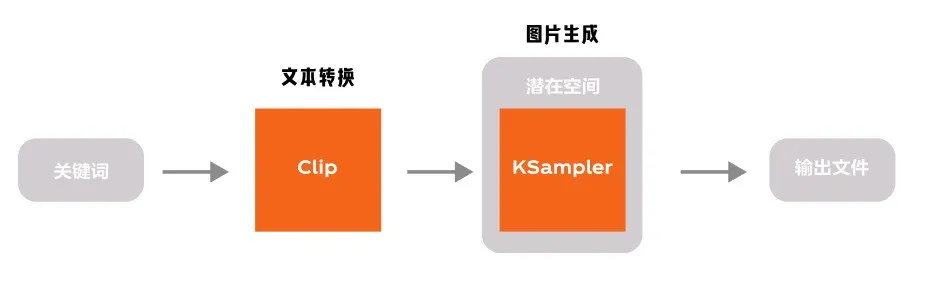
我们在前面的内容可以知道,潜在空间的内容不是人类可以读取的内容,文本的输入需要转换,同样图片的输出也需要转换,这个过程同样使用了 VAE 模型。
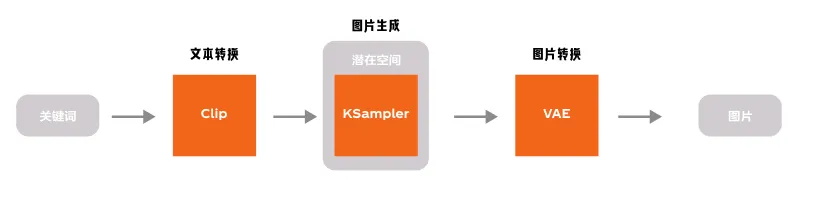
这就是最基础的文生图过程,现在再回看 ComfyUI 的基础模型是不是会清晰很多。
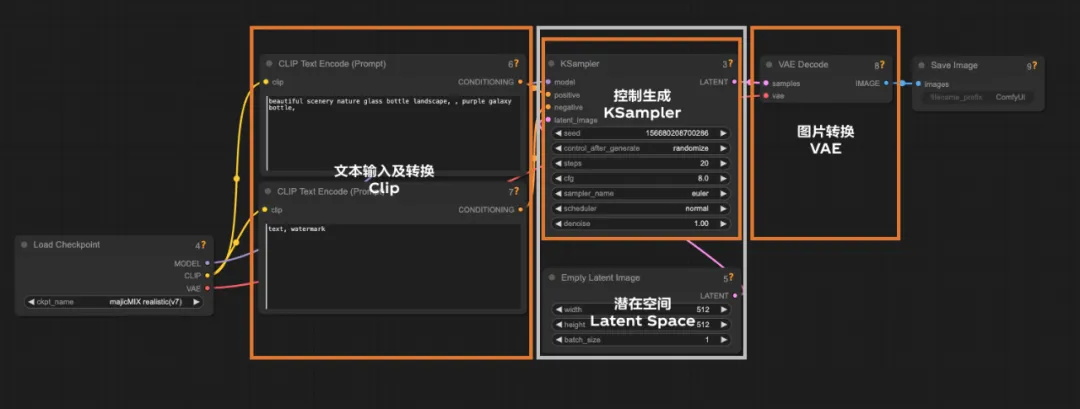
而整个工作流的运行由大模型控制,所以在工作流以 CheckPoint 节点加载扩散模型为起点,CheckPoint 节点还会提供适当的 VAE 和 Clip 模型。但这并不影响工作流中使用自己选择的 VAE 和 Clip 模型。
到这里我们就已经完全了解了一个最基础的文生图过程和相对应的 ComfyUI 节点,更多进阶内容大家都可以更加深入的探索。
三、与 WebUI 的差异
作为现在最火爆的两大创作工具,WebUI 开箱即用,基本功能齐全,社区也有很多的插件支持,入门比较简单,适合新手,但是可定制性稍微差点,很多作品不容易传播复现,使用 API 进行操作也有一定的难度。
ComfyUI 虽然出来的晚一点,但是它的可定制性很强,可以让创作者搞出各种新奇的玩意,通过工作流的方式,也可以实现更高的自动化水平,创作方法更容易传播复现,发展势头特别迅猛。两者对比有非常多显著的差别。
1. ComfyUI 对显卡比较友好
即使是 GPU 小于 3G 的情况下也能正常工作。它占用的显存更少,在相同显存条件下能够生成更大尺寸的图像。同时,Mac 电脑也能顺利运行 ComfyUI(建议 M1 以上的电脑使用),虽然依旧达不到 Windos 的运行效率,但这也给 Mac 用户提供了一个可以使用 SD 生图的机会。而 WebUI 近乎抛弃了 12G 显存以下的用户,显存使用效率较低,更不提 Mac 用户。
2. ComfyUI 运行效率极大的提高
设计师通过 ComfyUI 和 Automatic1111 WebUI 运行了一批 20 张图像,以查看每张图像的总时间。这些图像基于 Stable Diffusion 1.5 模型,分辨率为 512x768。作为参考,使用的是 RTX 3060(12GB VRAM)。最后的结果如下
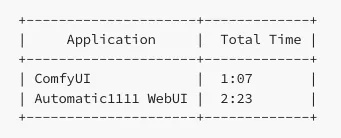
WebUI 要花费 ComfyUI 两倍多的时间,这是一个相当大的差距。当你使用 SD 生成视频渲染每一帧时这种时间差异会更加明显。
3. ComfyUI 可以实现实时预览
用户能够即时看到生成结果。这归功于节点拼接的高自由度,你可以在任何一个位置插入图片生成的功能节点,这样就可以在你想要预览图片的位置实时预览图片生成效果。
4. ComfyUI 可以完全实现工作流的复用
ComfyUI 的工作流可以单独作为 Json 文件保存,你可以通过下载的工作流文件直接使用理想效果的工作流,也可以在这份文件上进行任意的修改和添加。值得注意的是,通过 ComfyUI 生成的图片原文件也保留着工作流数据,也就是说,你只要下载社交媒体上设计师上传的图片原文件拖拽放入 ComfyUI 中,工作流会被立刻复现。
5. 与 WebUI 共通模型
WebUI 与 ComfyUI 本质都是使用 Stable Diffusion 大模型进行生图,只是使用方式不同,所以如果你是 WebUI 的老用户,你可以直接将 WebUI 中使用的模型与 ComfyUI 共通,过程非常简单,后面会提到。
四、使用技巧
在这里为新手的设计师提供一些你一定会用到的使用技巧:
1. ComfyUI Manager
ComfyUI 是完全通过节点组成,所以下载不同的节点是最开始就会遇到的问题。ComfyUI Manager 作为一个节点,你可以将它看作一个插件,它可以下载几乎所有你能使用到的节点,并且提供了更新、管理自定义节点等等的功能。下载了它几乎等于你不会再通过 Github 安装节点。
安装完成 ComfyUI Manager 后,重启 ComfyUI,在右边可以找到一个「manager」点击就可以进入插件界面。

其中有两个最常用的功能就是搜索安装节点和一键安装工作流中的所有缺失节点。
ComfyUI Manager:github.com/ltdrdata/ComfyUI-Manager
2. 将 WebUI 中的模型导入 ComfyUI
用过 WebUI 的设计师应该已经下载了很多自己顺手的模型,这些模型在 ComfyUI 中也是通用的,所以我们只需要共享这些模型就可以使用
具体流程如下:
- 在 ComfyUI 目录中,有一个 extra_model_paths.yaml.example 文件,将其重命名为 extra_model_paths.yaml
- 打开该文件,找到 base_path:path/to/stable-diffusion-webui/,将路径替换为你的 WebUI 的路径,例如 base_path:D/StableDiffusion/stable-diffusion-webui/
- 最后重启 ComfyUI,你就可以在 Load Checkpoint 中的 Ckpt_name 中找到
结语
设计是一门不断发展的艺术和科学。保持对新技术、新方法的好奇心,是我们不停向上走的助力。但尽管 AI 可以提供很多帮助,设计的核心仍然是人类的情感和体验。确保设计作品能够与用户产生情感共鸣,始终保持人性化的触感。希望我们能够继续发挥创造力和想象力,利用 AI 和其他新技术,创造出更多美丽、有用且有意义的设计作品。
为了帮助大家更好地掌握 ComfyUI,我在去年花了几个月的时间,撰写并录制了一套ComfyUI的基础教程,共六篇。这套教程详细介绍了选择ComfyUI的理由、其优缺点、下载安装方法、模型与插件的安装、工作流节点和底层逻辑详解、遮罩修改重绘/Inpenting模块以及SDXL工作流手把手搭建。
由于篇幅原因,本文精选几个章节,详细版点击下方卡片免费领取

一、ComfyUI配置指南
- 报错指南
- 环境配置
- 脚本更新
- 后记
- …
二、ComfyUI基础入门
- 软件安装篇
- 插件安装篇
- …
三、 ComfyUI工作流节点/底层逻辑详解
- ComfyUI 基础概念理解
- Stable diffusion 工作原理
- 工作流底层逻辑
- 必备插件补全
- …
四、ComfyUI节点技巧进阶/多模型串联
- 节点进阶详解
- 提词技巧精通
- 多模型节点串联
- …
五、ComfyUI遮罩修改重绘/Inpenting模块详解
- 图像分辨率
- 姿势
- …

六、ComfyUI超实用SDXL工作流手把手搭建
- Refined模型
- SDXL风格化提示词
- SDXL工作流搭建
- …

由于篇幅原因,本文精选几个章节,详细版点击下方卡片免费领取